I am a Principal Researcher at Microsoft Research. My research program focuses on developing interpretable machine learning and AI algorithms to study how genetic effects and their interactions impact human health. As part of this work, I co-lead Project Ex Vivo, a collaborative effort between Microsoft and the Broad Institute focused on defining, engineering, and targeting cell states in cancer. I have been featured on Forbes 30 Under 30 and The Root 100 Most Influential African Americans list. I also received an Alfred P. Sloan Research Fellowship, a Packard Foundation Fellowship for Science and Engineering, a COPSS Emerging Leader Award, and the Annie T. Randall Innovator Award from the Biometrics Section of the ASA.
I earned my PhD from the Department of Statistical Science at Duke University where I was co-advised by Sayan Mukherjee and Kris C. Wood. As a Duke Dean’s Graduate Fellow and NSF Graduate Research Fellow I completed my PhD dissertation entitled "Bayesian Kernel Models for Statistical Genetics and Cancer Genomics" which was awarded a Leonard J. Savage Award in Applied Methodology. I also received my Bachelor of Science degree in Mathematics from Clark Atlanta University.
Interpretability in Machine Learning Methods
Machine learning algorithms have become frequently used in genomic studies because they typically exhibit high predictive accuracy. However, recently, these same algorithms have also become criticized as “black box” techniques. We look to build methods that over this challenge.
Dissecting Genetic Architecture of Complex Traits
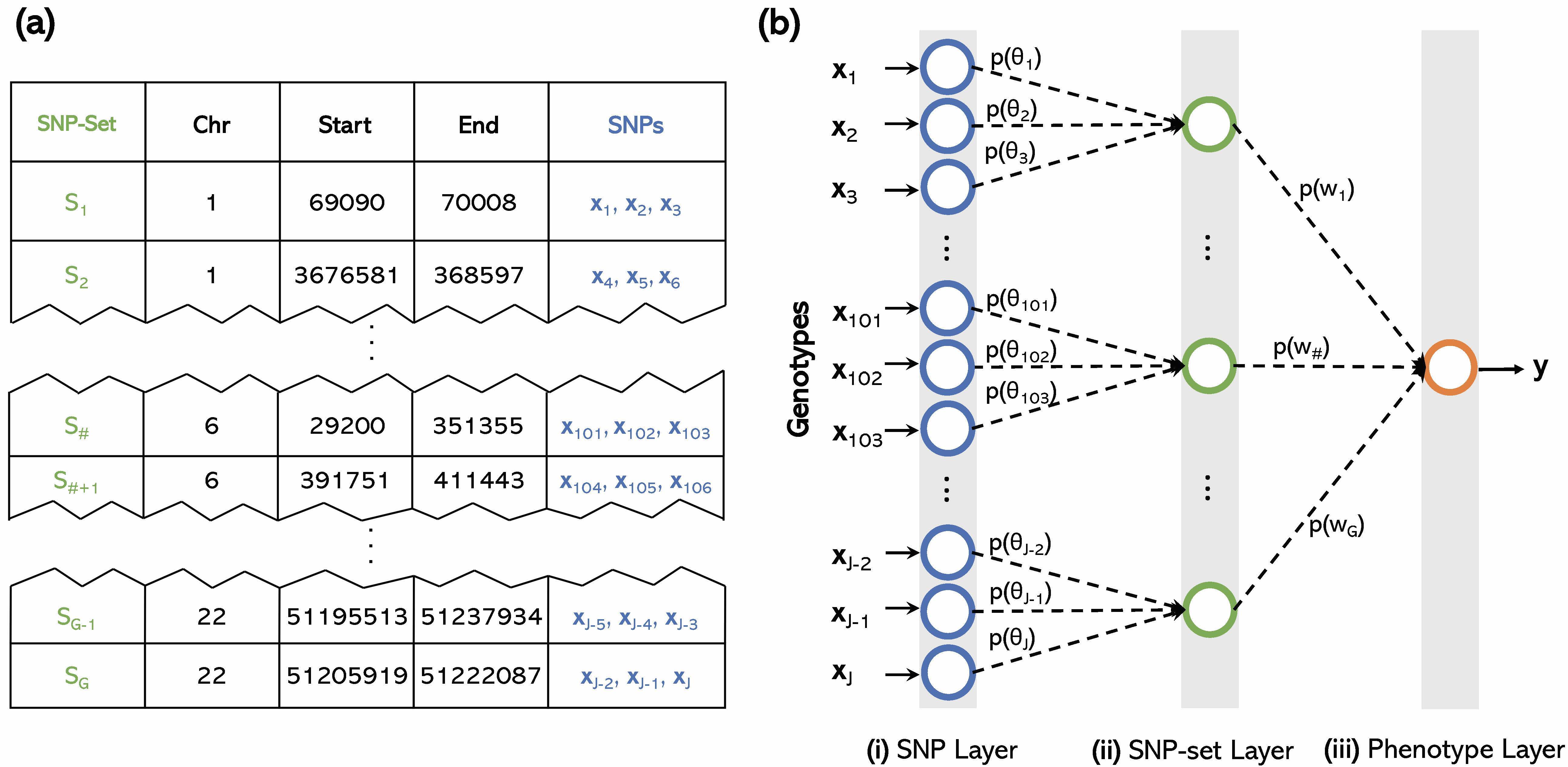
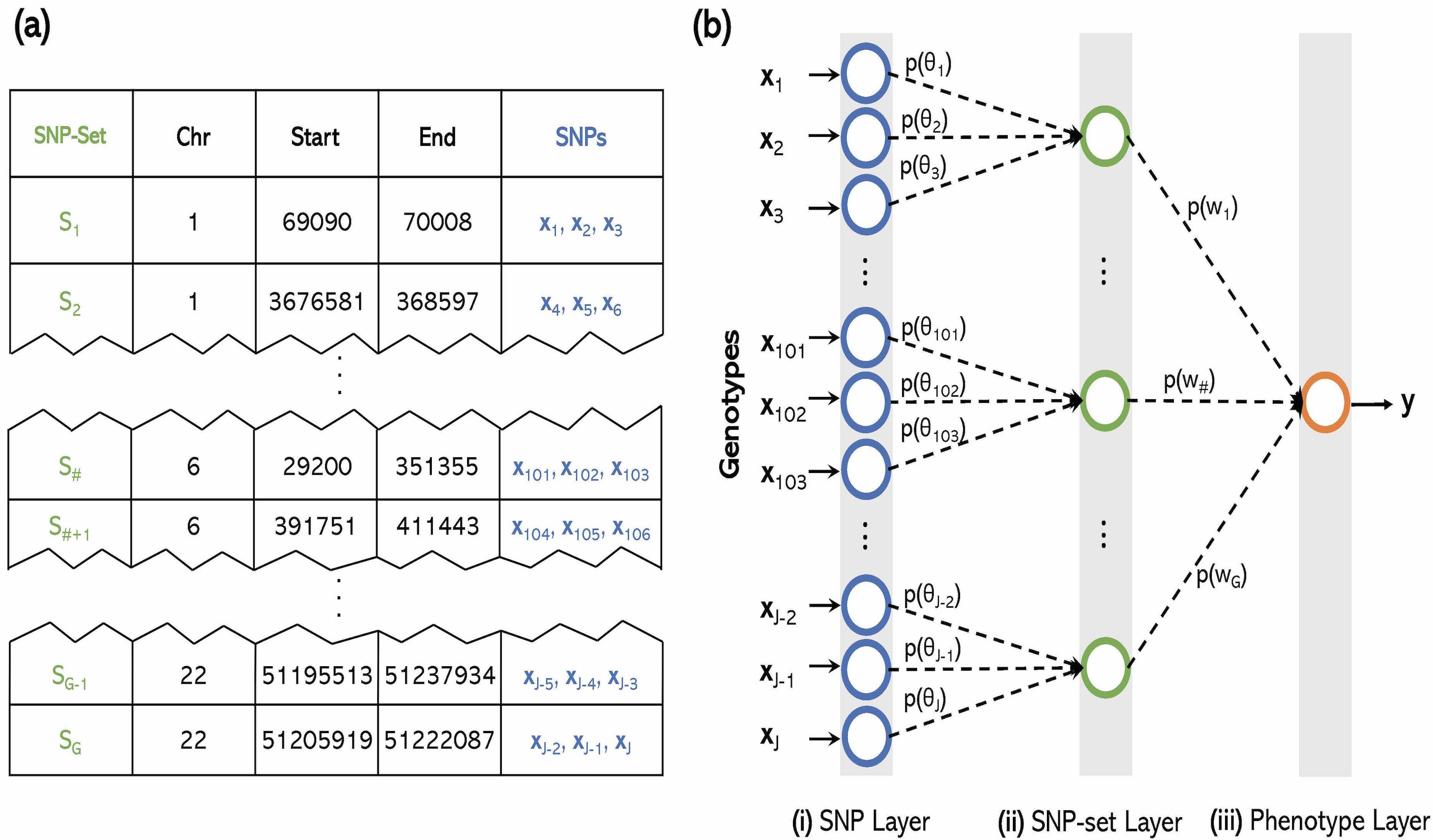
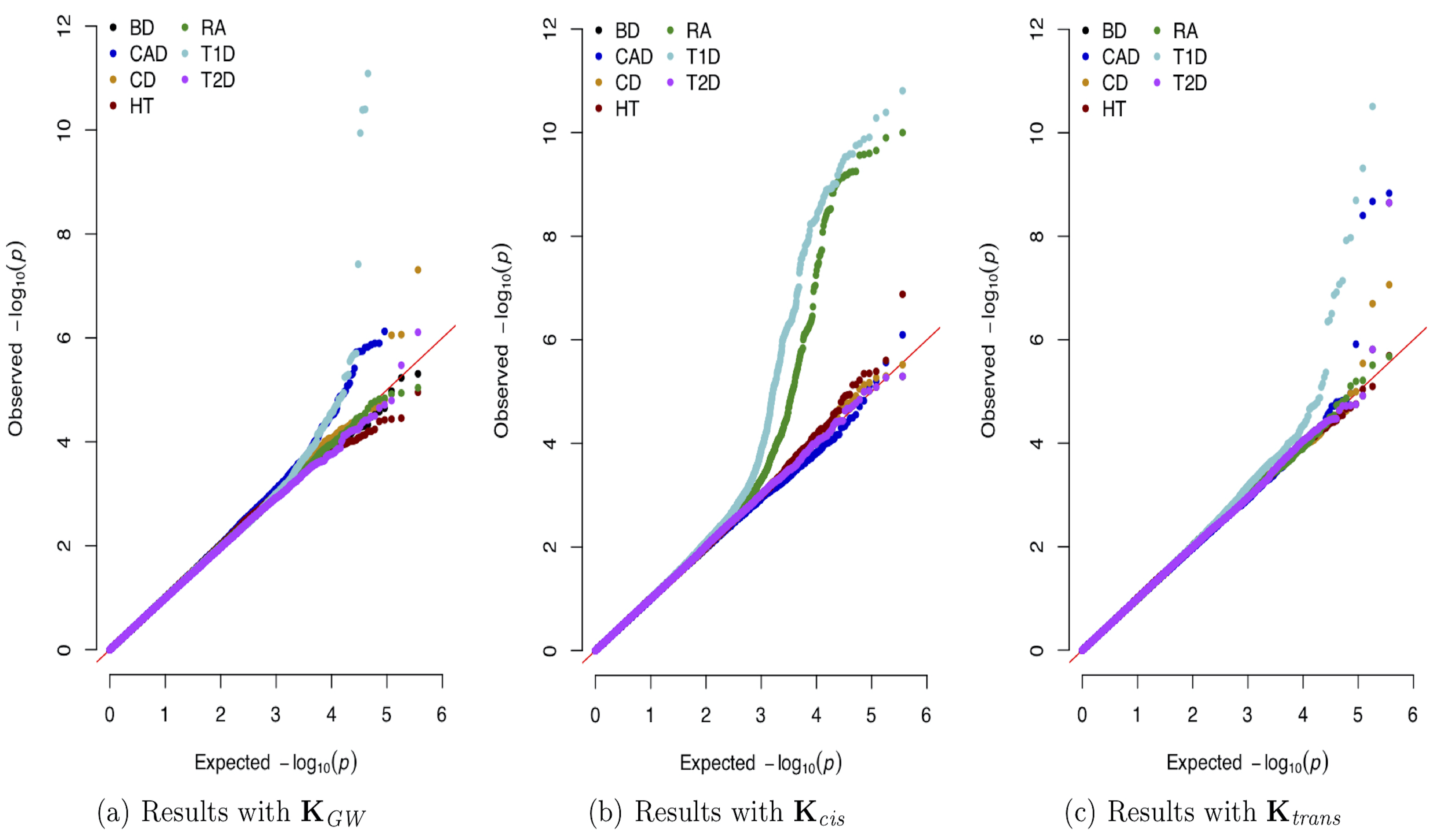
The explosion of large-scale genomic datasets has provided the unique opportunity to move beyond the traditional LMM framework within GWAS. We build novel ML methods that exhibit power for complex traits that are driven by non-additive genetic variation (e.g., gene-by-gene interactions).
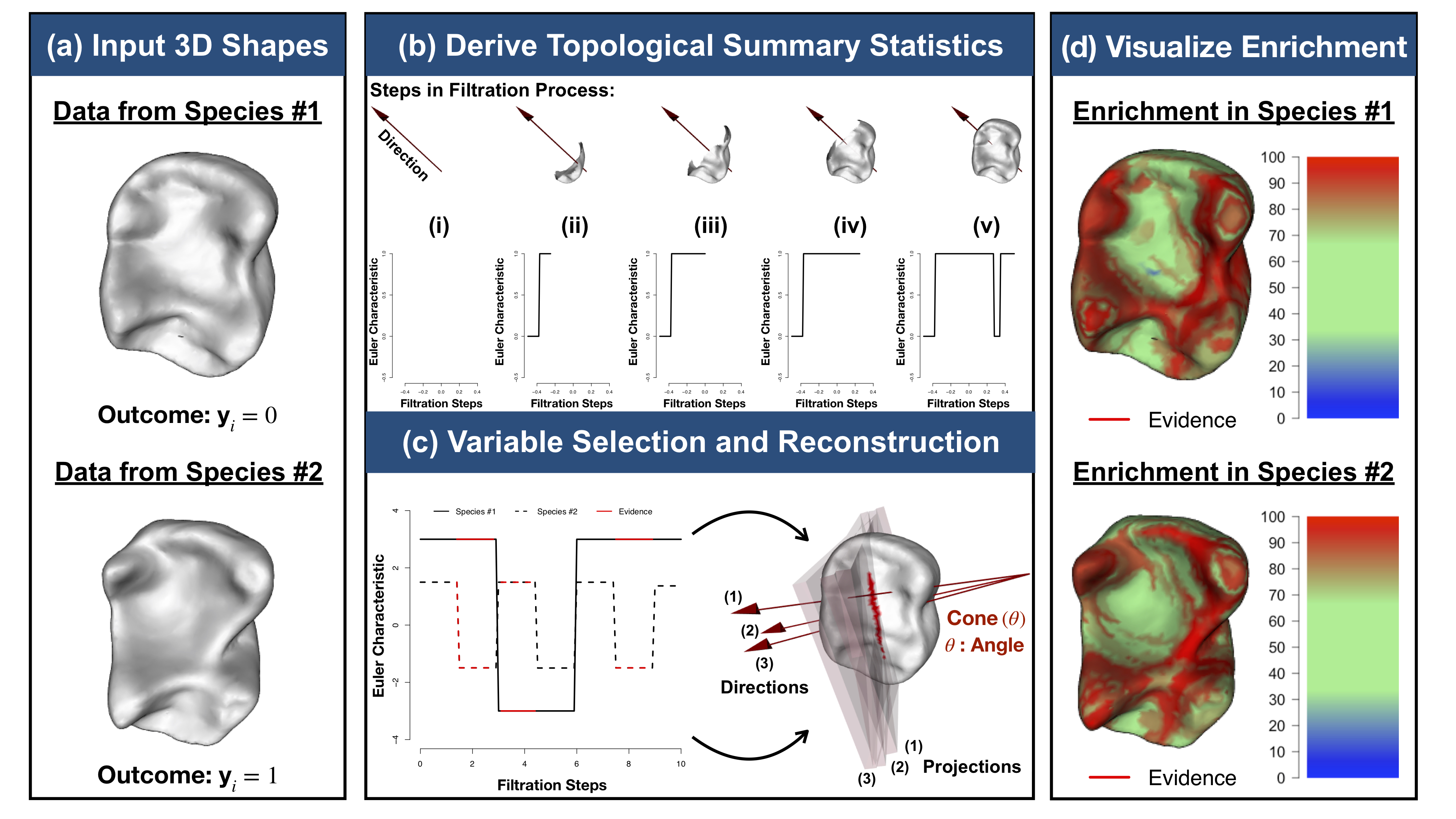
Modeling 3D Variation with Topological Summaries
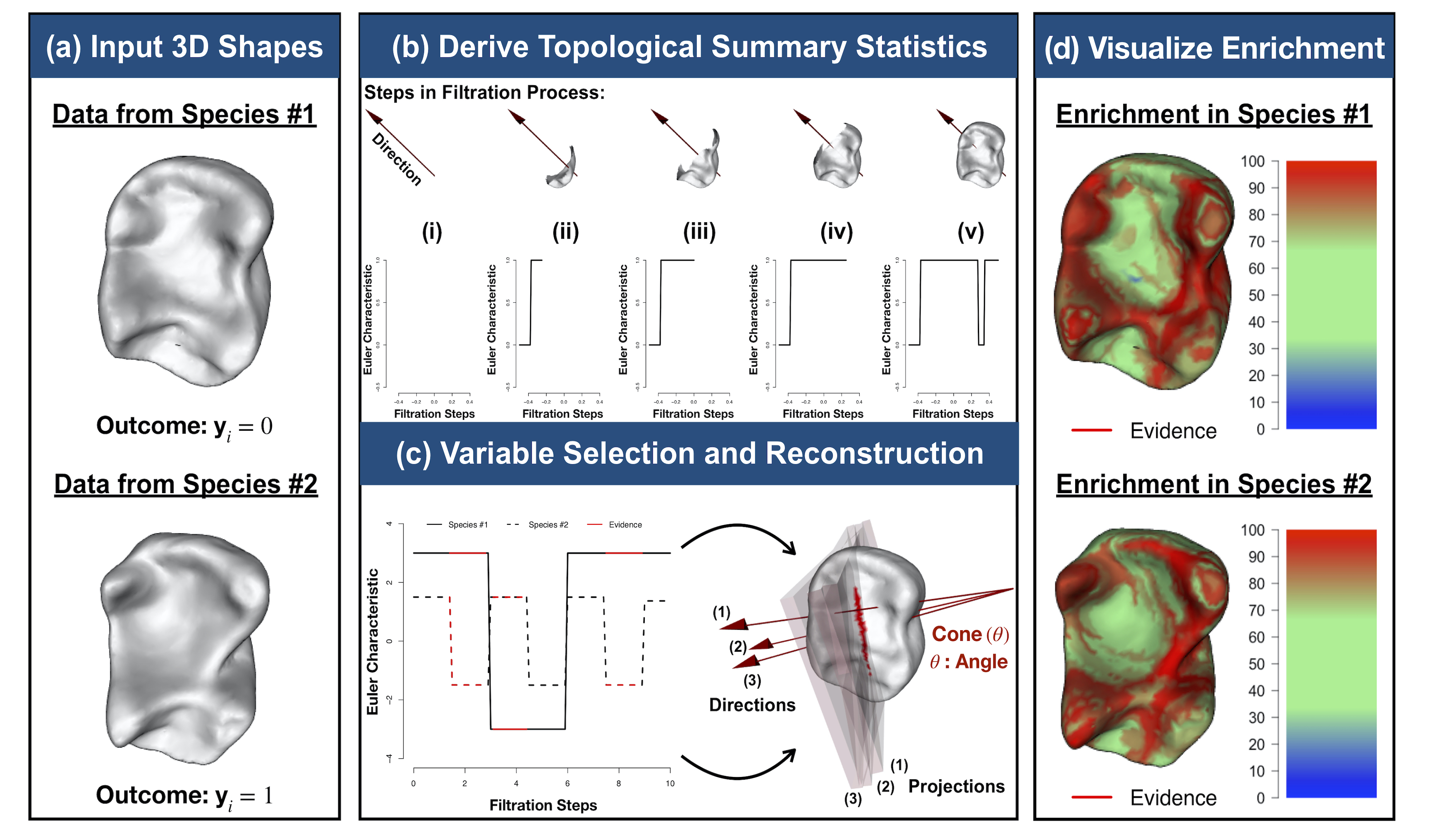
It has been a longstanding challenge to implement an analogue of variable selection with 3D shapes as the covariates in a regression model. Here, we develop novel statistical and topological data analytic (TDA) pipelines for sub-image selection where the goal is to identify the physical features of 3D shapes that best explain the variation between two phenotypic classes.
AI for Cancer Genomics and Pharmacology
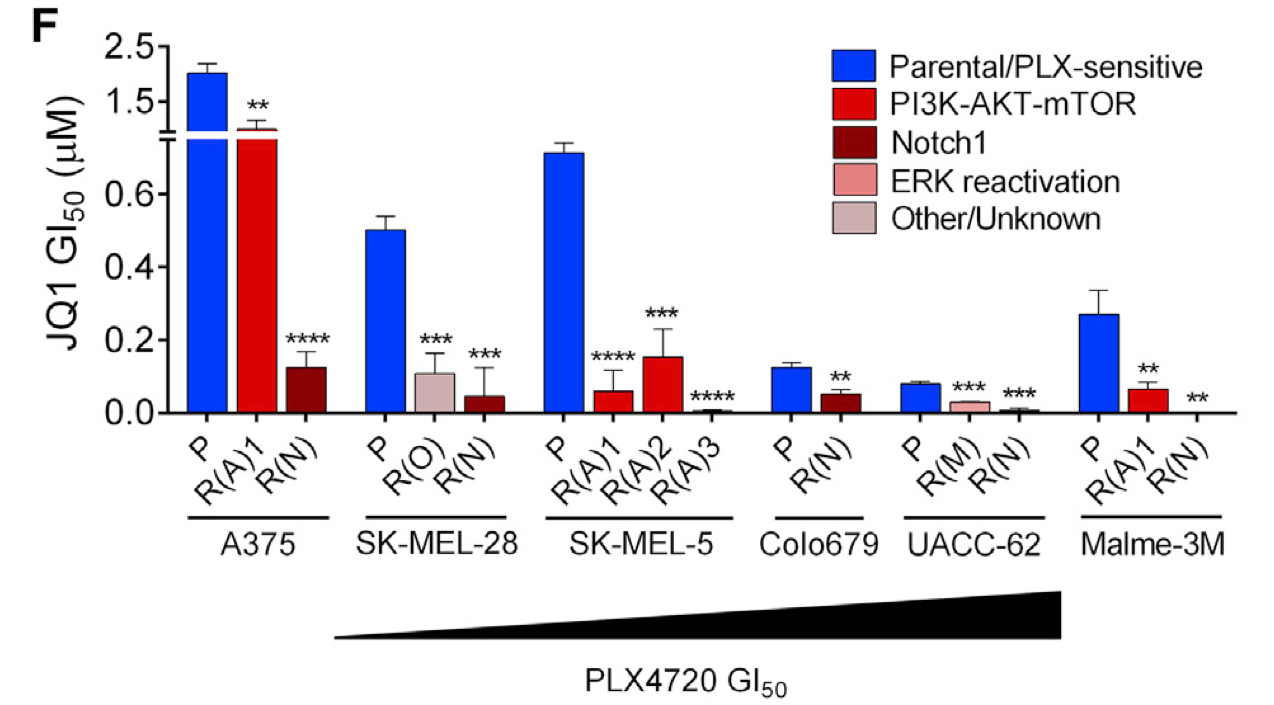
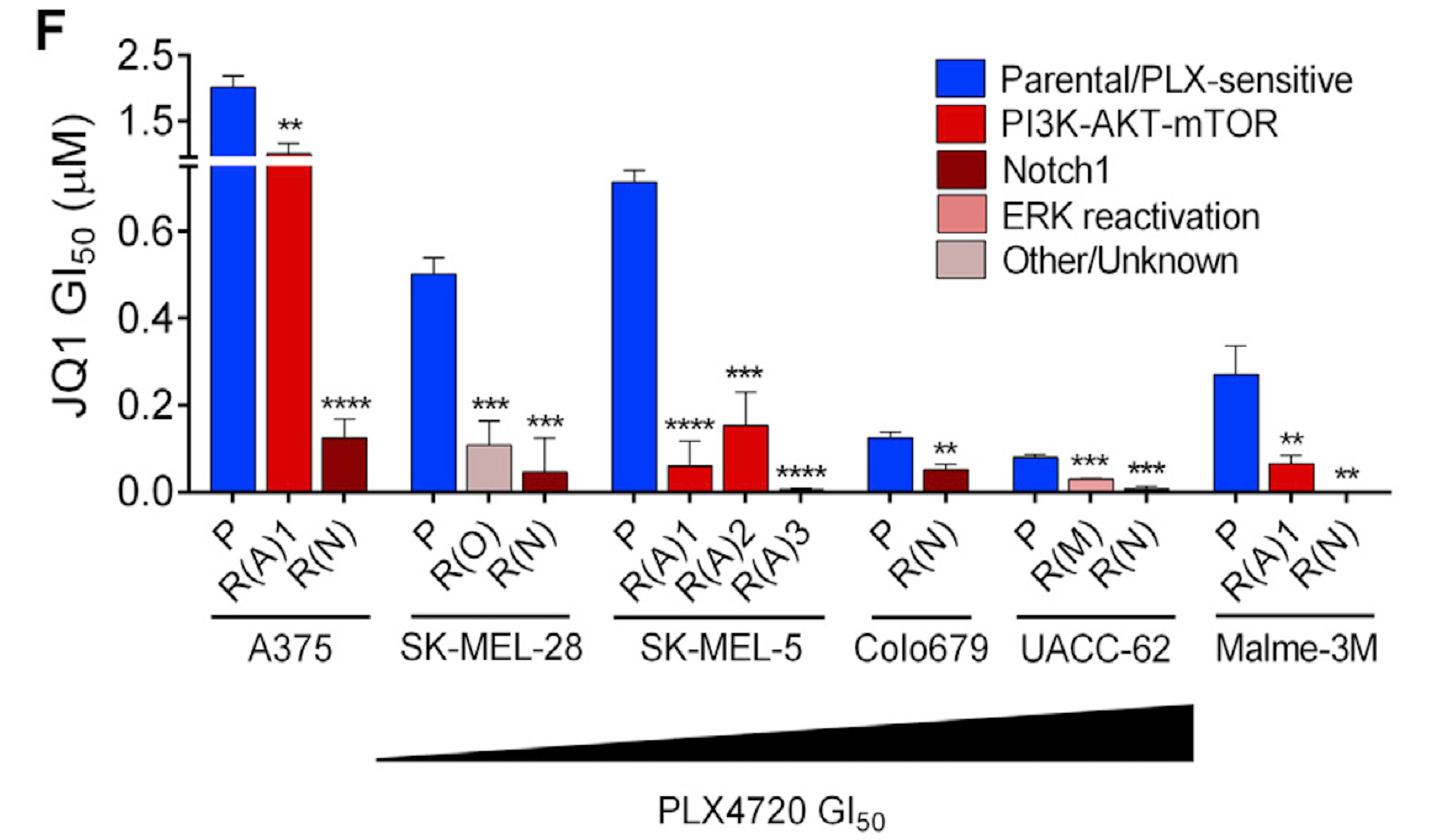
Targeted therapies aimed to inhibit oncogenic signaling within many cancer subtypes have been proven to have high initial clinical responses, but relapse in these patients is almost inevitable. To better understand this phenomenon, we develop AI algorithms that define rigorous transcriptional signatures of cancer recurrence and therapeutic resistance.
Publications Key: * co-first authors; † co-senior authors; # corresponding author(s); advisee
Preprint(s):
- M. Pizurica, E. Zimmermann, N. Tenenholtz, J. Hall, O. Gevaert, A.P. Amini, L. Crawford, and K.A. Severson#. JASPR: joint spatial representation learning of histology and spatial genomics for improved virtual genomic screening and clinical prognostication. arXiv. 2606.28395. [Preprint]
- E. Hayir, L. Crawford, and A.X. Lu#. MorphoHELM: a comprehensive benchmark for evaluating representations for microscopy-based morphology assays. arXiv. 2605.15383. [Preprint] [Software]
- A. Vijayaraghavan, L. Crawford, K. Saboo, A.P. Amini, A.M. Conard, A.L. Olsen, L.M. Chahine, and K.A. Severson#. A biologically annotated neural network for proteomic discovery in Parkinson’s disease. medRxiv. 2026.04.29.26351681. [Preprint]
- A.G. Duncan, M.E. Consens, L. Crawford, J.A. Mitchell, A.M. Moses, K.K. Yang, and A.X. Lu#. Evolutionary conditioning enables guided generation of functionally diverse enhancers. bioRxiv. 2026.04.13.718170. [Preprint] [Software]
- E. Redekop, E. Zimmermann, A.P. Amini, A.X. Lu, N. Tenenholtz, J. Hall, L. Crawford, and K.A. Severson#. Multimodal alignment improves generalizability of genomic biomarker prediction in computational pathology. arXiv. 2603.00193. [Preprint]
- T. Richter, E. Zimmermann, J. Hall, F.J. Theis, S. Raghavan†, P.S. Winter†, A.P. Amini†, and L. Crawford†#. Beyond alignment: synergistic integration is required for multimodal cell foundation models. bioRxiv. 2026.02.23.707420. [Preprint] [Software]
- Z. Navidi, A. Thoutam, M. Hughes, S. Raghavan†, P.S. Winter†, L. Crawford†#, and A.P. Amini†#. Adaptive resampling for improved machine learning in imbalanced single-cell datasets. bioRxiv. 2025.02.19.639127. [Preprint] [Software]
- S. Surasinghe*, S.N. Manivannan*, L. Crawford, and C.B. Ogbunugafor#. Classification and regression trees clarify the role of epistasis and environment in genotype-phenotype maps. EcoEvoRxiv. 10297. [Preprint]
- A. Nadig#, A. Thoutam, M. Hughes, A. Gupta, A.W. Navia, N. Fusi, S. Raghavan†, P.S. Winter†, A.P. Amini†#, and L. Crawford†#. Consequences of training data composition for deep learning models in single-cell biology. bioRxiv. 2025.02.19.639127. [Preprint] [Software]
- A.M. Wong# and L. Crawford#. Rethinking cancer drug synergy prediction: a call for standardization in machine learning applications. bioRxiv. 2024.12.24.630216. [Preprint] [Software]
- S. Surasinghe, S.N. Manivannan, S.V. Scarpino, L. Crawford, and C.B. Ogbunugafor#. Structural causal influence (SCI) captures the forces of social inequality in models of disease dynamics. arXiv. 2409.09096. [Preprint]
- P.S. Winter*#, M.L. Ramseier*, A.W. Navia*, S. Saksena, H. Strouf, N. Senhaji, A. DenAdel, M. Mirza, H.H. An, L. Bilal, P. Dennis, C.S. Leahy, K. Shigemori, J. Galves-Reyes, Y. Zhang, F. Powers, N. Mulugeta, A.J. Gupta, N. Calistri, A. Van Scoyk, K. Jones, H. Liu, K.E. Stevenson, S. Ren, M.R. Luskin, C.P. Couturier, A.P. Amini, S. Raghavan, R.J. Kimmerling, M.M. Stevens, L. Crawford, D.M. Weinstock, S.R. Manalis†, A.K. Shalek†#, and M.A. Murakami†#. Mutation and cell state compatibility is required and targetable in Ph+ acute lymphoblastic leukemia minimal residual disease. bioRxiv. 2024.06.06.597767. [Preprint]
- E.T. Winn-Nuñez#, H. Witt, D. Bhaskar, R.Y. Huang, J.S. Reichner, I.Y. Wong, and L. Crawford#. Generative modeling of biological shapes and images using a probabilistic α-shape sampler. bioRxiv. 2024.01.09.574919. [Preprint] [Software]
- K. Meng#, M. Ji, J. Wang, K. Ding, H. Kirveslahti, A. Eloyan, and L. Crawford. Statistical inference on grayscale images via the Euler-Radon transform. arXiv. 2308.14249. [Preprint] [Software]
- M.C. Turchin#, G. Darnell, L. Crawford#, and S. Ramachandran#. Pathway analysis within multiple human ancestries reveals novel signals for epistasis in complex traits. bioRxiv. 2020.09.24.312421. [Preprint] [Software]
- W. Cheng, G. Darnell, S. Ramachandran, and L. Crawford#. Generalizing variational autoencoders with hierarchical empirical Bayes. arXiv. 2007.10389. [Preprint] [Software]
- K.E. Ware, S. Gupta, J. Eng, G. Kemeny, B.J. Puviindran, W.C. Foo, L. Crawford, R.G. Almquist, D. Runyambo, B.C. Thomas, M.U. Sheth, A. Agarwal, M. Pierobon, E.F. Petricoin, D.L. Corcoran, J. Freedman, S.R. Patierno, T. Zhang, S. Gregory, Z. Sychev, J.M. Drake, A.J. Armstrong#, and J.A. Somarelli#. Convergent evolution of p38/MAPK activation in hormone resistant prostate cancer mediates pro-survival, immune evasive, and metastatic phenotypes. bioRxiv. 2020.04.22.050385. [Preprint]
- J. Ish-Horowicz*, D. Udwin*, K. Scharfstein, S.R. Flaxman, L. Crawford#, and S.L. Filippi#. Interpreting deep neural networks through variable importance. arXiv. 1901.09839. [Preprint] [Software]
- L. Crawford# and X. Zhou#. Genome-wide marginal epistatic association mapping in case-control studies. bioRxiv. 374983. [Preprint] [SI] [Software]
2026:
- M.E. Consens#, K.K Yang, J. Hall, A.M. Conard, B. Wang, L. Crawford, A. Moses, and A.X. Lu (2026). Predicting evolutionary rate as a pretraining task improves genome language model representations. International Conference on Machine Learning (ICML). Accepted. [Preprint]
- A. DenAdel, M. Hughes, A. Thoutam, A. Gupta, A.W. Navia, N. Fusi, S. Raghavan†, P.S. Winter†, A.P. Amini†#, and L. Crawford†# (2026). Evaluating the role of pre-training dataset size and diversity on single-cell foundation model performance. Nature Methods. 23: 1447-1457. [Journal Link] [Software] [Springer Nature SharedIt] [Research Briefing]
- A.M. Conard, M. Hughes, J. Hall, N. Tenenholtz, E. Zimmermann, L. Crawford, A.P. Amini#, and K. Severson# (2026). Tackling the complexity of cancer with generative models. Cell. 189: 2218-2231. [Journal Link]
- S. Cultrera di Montesano*#, D. D'Ascenzo*, S. Raghavan†, A.P. Amini†, P.S. Winter†#, and L. Crawford†#. Improving atlas-scale single-cell annotation models with hierarchical cross-entropy loss. Nature Computational Science. 6: 243-249. [Journal Link] [Software]
- C. Nwizu, M. Hughes, M.L. Ramseier, A. Navia, A.K. Shalek, N. Fusi, S. Raghavan†, P.S. Winter†, A.P. Amini†#, and L. Crawford†#. Scalable nonparametric clustering with unified marker gene selection for single-cell RNA-seq data. Cell Reports Methods. 6(3): 101329. [Journal Link] [Software] [Documentation]
- R. Vinod, A.P. Amini, L. Crawford#, and K.K. Yang#. Trainable subnetworks reveal insights into structure knowledge organization in protein language models. PLOS Computational Biology. 22(2): e1013925. [PDF] [Software] [Journal Link]
- A.M. Wong*, C.P.G. Meier-Scherling*, and L. Crawford#. Characterizing clinical toxicity in cancer combination therapies. Bioinformatics. 42(2): btag007. [PDF] [Software] [Journal Link]
2025:
- X. Liu#, L. Crawford, and S. Ramachandran (2025). ML-MAGES: a machine learning framework for multivariate genetic association analyses with genes and effect size shrinkage. Genome Research. 35(12): 2691-2700. [PDF] [Software] [Journal Link]
- R.H. Gindra*, G. Palla*, M. Nguyen, S.J. Wagner, M. Tran, F.J. Theis, D. Saur, L. Crawford†#, and T. Peng†# (2025). A large-scale benchmark of cross-modal learning for histology and gene expression in spatial transcriptomics. Proceedings of the IEEE/CVF International Conference on Computer Vision. 1182-1192. [Proceedings Link] [SI] [Software]
- J. Stamp#, S. Pattillo Smith, D. Weinreich, and L. Crawford# (2025). Sparse modeling of interactions enables fast detection of genome-wide epistasis in biobank-scale studies. American Journal of Human Genetics. 112(9): 2198-2212. [PDF] [Software] [Documentation] [Journal Link]
- J. Stamp# and L. Crawford# (2025). Epistasis in cardiac traits. Nature Cardiovascular Research. 4: 655-656. (News & Views) [Journal Link] [Springer Nature SharedIt]
- W. Sloneker#, S. Patel, HJ. Wang, L. Crawford, and R. Singh# (2025). BetaExplainer: a probabilistic method to explain graph neural networks. Journal of Statistical Theory and Applications. 24: 469-488. [PDF] [Software] [Journal Link]
- K.Z. Kedzierska, L. Crawford, A.P. Amini, and A.X. Lu# (2025). Zero-shot evaluation reveals limitations of single-cell foundation models. Genome Biology. 26: 101. [PDF] [Software] [Journal Link] [Research Highlight]
- A. DenAdel, M.L. Ramseier, A. Navia, A.K. Shalek, S. Raghavan†, P.S. Winter†, A.P. Amini†, and L. Crawford†# (2025). Artificial variables help to avoid over-clustering in single-cell RNA-sequencing. American Journal of Human Genetics. 112(4): 940-951. [PDF] [Software] [Documentation] [Journal Link]
- I.E. Kim, Jr., C. Oduor, J. Stamp, M.A. Luftig, A.M. Moormann, L. Crawford†#, and J.A. Bailey†# (2025). Incorporation of Epstein-Barr viral variation implicates significance of LMP1 in survival prediction and prognostic subgrouping in Burkitt lymphoma. International Journal of Cancer. 156(11): 2188-2199. [PDF] [Software] [Journal Link]
- K. Meng#, J. Wang, L. Crawford, and A. Eloyan (2025). Randomness and statistical inference of shapes via the smooth Euler characteristic transform. Journal of the American Statistical Association. 120(549): 498-510. [PDF] [Software] [Journal Link]
- N. Liu*, W.E. Kattan*, B.E. Mead*, C. Kummerlowe*, T. Cheng, S. Ingabire, J.H. Cheah, C.K. Soule, A.Vrcic, J.K. McIninch, S. Triana, M. Guzman, T.T. Dao, J.M. Peters, K.E. Lowder, L. Crawford, A.P. Amini, P.C. Blainey, W.C. Hahn, B. Cleary, B. Bryson, P.S. Winter†, S. Raghavan†, and A.K. Shalek†# (2025). Scalable, compressed phenotypic screening using pooled perturbations. Nature Biotechnology. 43: 1324-1336. [PDF] [Journal Link] [Research Briefing]
2024:
- K. Li#, C. Chaguza, J. Stamp, Y.T. Chew, N.F.G. Chen, D. Ferguson, S. Pandya, N. Kerantzas, W. Schulz, Yale SARS-CoV-2 Genomic Surveillance Initiative, A.M. Hahn, C.B. Ogbunugafor, V.E. Pitzer, L. Crawford, D.M. Weinberger, and N.D. Grubaugh# (2024). Genome-wide association study between SARS-CoV-2 single nucleotide polymorphisms and virus copies during infections. PLOS Computational Biology. 20(9): e1012469. [PDF] [Software] [Journal Link]
- H. Xie, L. Crawford#, and A. Conard# (2024). Multioviz: an interactive platform for in silico perturbation and interrogation of gene regulatory networks. BMC Bioinformatics. 25: 249. [PDF] [Software] [Online Tool] [Journal Link]
- S. Pattillo Smith*, G. Darnell*, D. Udwin, J. Stamp, A. Harpak, S. Ramachandran†, and L. Crawford†# (2024). Discovering non-additive heritability using additive GWAS summary statistics. eLife. 13: e90459. [PDF] [Software] [Journal Link]
- J. Wrobel*#, E.C. Hector*, L. Crawford, L. D'Agostino McGowan, N. da Silva, J. Goldsmith, S. Hicks, M. Kane, Y. Lee, V. Mayrin, C.J. Paciorek, T. Usher, and J. Wolfson (2024). Partnering with authors to enhance reproducibility at JASA. Journal of the American Statistical Association. 119(546): 795-797. (Invited Comment) [Journal Link]
- E.T. Winn-Nuñez#, M. Griffin, and L. Crawford# (2024). A simple approach for local and global variable importance in nonlinear regression models. Computational Statistics & Data Analysis. 194: 107914. [PDF] [SI] [Software] [Journal Link]
2023:
- H. Adam#, F. Yin, M. Hu, N. Tenenholtz, L. Crawford, L. Mackey, and A. Koenecke (2023). Should I stop or should I go: early stopping with heterogeneous populations. Advances in Neural Processing Systems (NeurIPS). 36: 15799-15832. (Spotlight Paper) [Proceedings Link] [Software]
- J. Stamp#, A. DenAdel, D. Weinreich, and L. Crawford# (2023). Leveraging the genetic correlation between traits improves the detection of epistasis in genome-wide association studies. G3: Genes, Genomes, Genetics. 13(8): jkad118. [PDF] [Software] [Documentation] [Journal Link]
- C. Rios-Martinez, N. Bhattacharya, A.P. Amini, L. Crawford, and K.K. Yang# (2023). Deep self-supervised learning for biosynthetic gene cluster detection and product classification. PLOS Computational Biology. 19(5): e1011162. [PDF] [Software] [Journal Link]
- A. Conard, A. DenAdel, and L. Crawford# (2023). A spectrum of explainable and interpretable machine learning approaches for genomic studies. WIREs Computational Statistics. 15(5): e1617. [PDF] [Journal Link]
2022:
- B. Trippe#, B. Huang, E.A. DeBenedictis, B. Coventry, N. Bhattacharya, K.K. Yang, D. Baker, and L. Crawford# (2022). Randomized gates eliminate bias in sort-seq assays. Protein Science. 31(9): e4401. [PDF] [Journal Link]
- W. Cheng#, S. Ramachandran, and L. Crawford# (2022). Uncertainty quantification in variable selection for genetic fine-mapping using Bayesian neural networks. iScience. 25(7): 104553. (Spotlight Talk at the 10th RECOMB Satellite on Computational Methods in Genetics) [PDF] [SI] [Software] [Journal Link]
- W.S. Tang*, G.M. da Silva*, H. Kirveslahti, E. Skeens, B. Feng, T. Sudijono, K.K. Yang, S. Mukherjee, B. Rubenstein†, and L. Crawford†# (2022). A topological data analytic approach for discovering biophysical signatures in protein dynamics. PLOS Computational Biology. 18(5): e1010045. [PDF] [SI] [Software] [Journal Link]
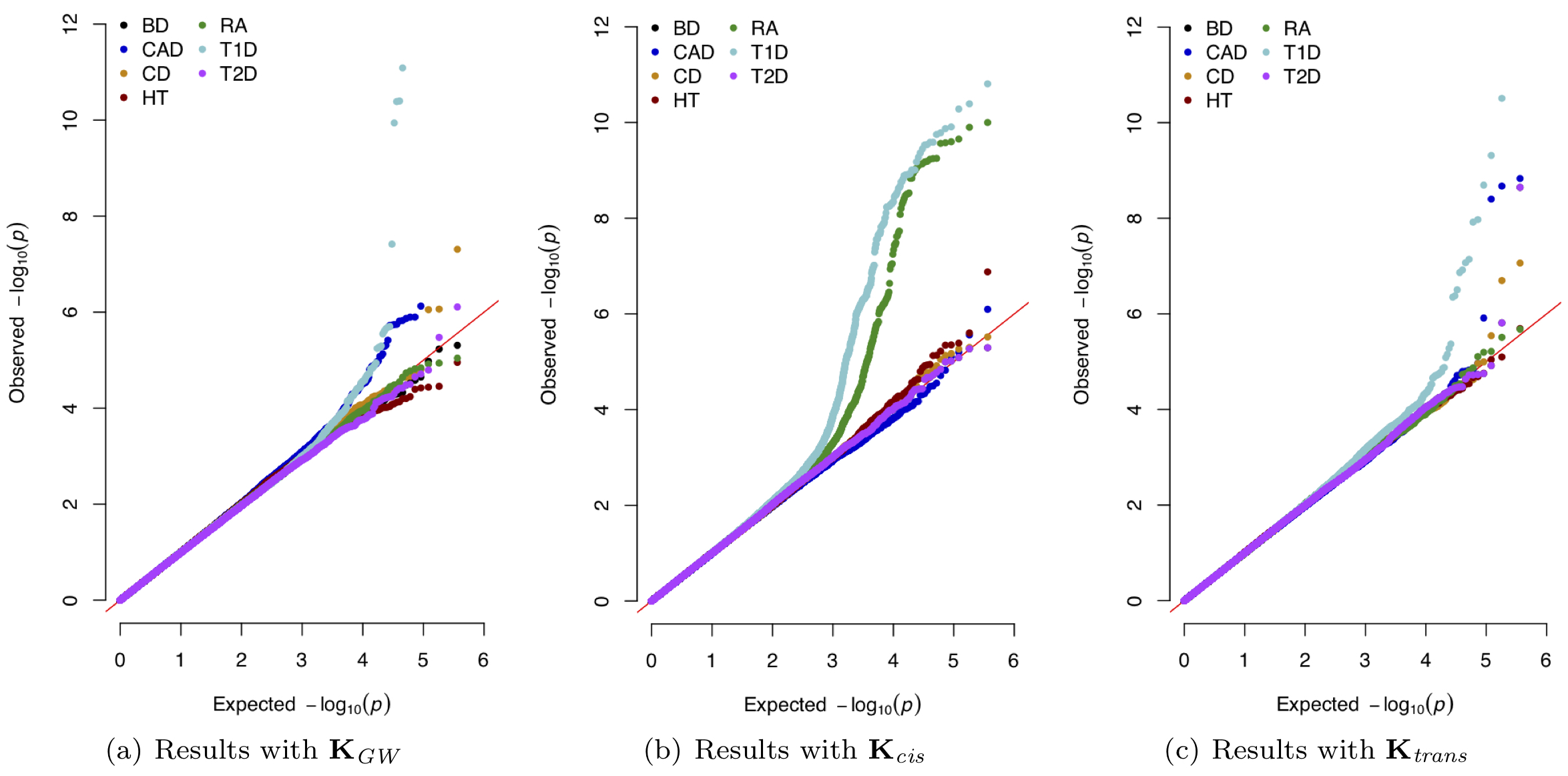
- S. Pattillo Smith, S. Shahamatdar, W. Cheng, S. Zhang, J. Paik, M. Graff, C. Haiman, T.C. Matise, K.E. North, U. Peters, E. Kenny, C. Gignoux, G. Wojcik, L. Crawford†, and S. Ramachandran†# (2022). Enrichment analyses identify shared associations for 25 quantitative traits in over 600,000 individuals from seven diverse ancestries. American Journal of Human Genetics. 109: 871-884. [PDF] [Software] [Journal Link] [Editorial]
2021:
- S. Raghavan*, P.S. Winter*#, A.W. Navia*, H.L. Williams*, A. DenAdel, R.L. Kalekar, J. Galvez-Reyes, K.E. Lowder, J. Galvez-Reyes, R.L. Kalekar, N. Mulugeta, K.S. Kapner, M.S. Raghavan, A.A. Borah, N. Liu, S.A. Väyrynen, A. Dias Costa, R.W.S. Ng, J. Wang, E.K. Hill, D.Y. Ragon, L.K. Brais, A.M. Jaeger, L.F. Spurr, Y.Y. Li, A.D. Cherniack, M.A. Booker, E.F. Cohen, M.Y. Tolstorukov, I. Wakiro, A. Rotem, B.E. Johnson, J.M. McFarland, E.T. Sicinska, T.E. Jacks, R.J. Sullivan, T.E. Clancy, K. Perez, D.A. Rubinson, K. Ng, J.M. Cleary, L. Crawford, S.R. Manalis, J.A. Nowak, B.R. Wolpin†, W.C. Hahn†, A.J. Aguirre†#, and A.K. Shalek†# (2021). Microenvironment drives cell state, plasticity, and drug response in pancreatic cancer. Cell. 184(25): 6119-6137. [PDF] [Journal Link]
- M. Kamariza#, L. Crawford#, D. Jones#, and H.K. Finucane# (2021). Misuse of the term "trans-ethnic" in genomics research. Nature Genetics. 50: 1520-1521. [Journal Link] [Editorial]
- P. Demetci*, W. Cheng*, G. Darnell, X. Zhou, S. Ramachandran, and L. Crawford# (2021). Multi-scale inference of genetic architecture using biologically annotated neural networks. PLOS Genetics. 17(8): e1009754. [PDF] [SI] [Software] [Journal Link]
- D.E. Runcie#, J. Qu, H. Cheng, and L. Crawford (2021). Mega-scale linear mixed models for genomic predictions with thousands of traits. Genome Biology. 22: 213. [PDF] [SI] [Software] [Journal Link]
- B. Wang*, T. Sudijono*, H. Kirveslahti*, T. Gao, D.M. Boyer, S. Mukherjee†, and L. Crawford†# (2021). A statistical pipeline for identifying physical features that differentiate classes of 3D shapes. Annals of Applied Statistics. 15(2): 638-661. [PDF] [SI] [Software] [Journal Link]
- A.N. Spierer#, J.A. Mossman, S. Pattillo Smith, L. Crawford, S. Ramachandran, and D.M. Rand# (2021). Natural variation in the regulation of neurodevelopmental genes modifies flight performance in Drosophila. PLOS Genetics. 17(3): e1008887. [PDF] [SI] [Software] [Journal Link]
- B.A. Borden, Y. Baca, J. Xiu, F. Tavora, I. Winer, B.A. Weinberg, A.M. VanderWalde, S. Darabi, W.M. Korn, A.P. Mazar, F.J. Giles, L. Crawford, H. Safran, W.S. El-Deiry, and B.A. Carneiro# (2021). The landscape of glycogen synthase kinase-3 beta (GSK-3b) genomic alterations in cancer. Molecular Cancer Therapeutics. 20(1): 183-190. [Journal Link]
2020:
- L. Crawford#, A. Monod#, A.X. Chen, S. Mukherjee, and R. Rabadán (2020). Predicting clinical outcomes in glioblastoma: an application of topological and functional data analysis. Journal of the American Statistical Association. 115(531): 1139-1150. [PDF] [SI] [Software] [Journal Link]
- J.S. Sadick, L. Crawford, H.C. Cramer, C. Franck, S.A. Liddelow, and E.M. Darling# (2020). Generating cell type-specific protein signatures from non-symptomatic and diseased tissues. Annals of Biomedical Engineering. 48: 2218-2232. [Journal Link]
- W. Cheng, S. Ramachandran#, and L. Crawford# (2020). Estimation of non-null SNP effect size distributions enables the detection of enriched genes underlying complex traits. PLOS Genetics. 16(6): e1008855. [PDF] [SI] [Software] [Journal Link]
- K.H. Lin*, J.C. Rutter*, A. Xie, E.T. Winn, B. Pardieu, R. Dal Bello, Y.R. Ahn, Z. Dai, R.T. Sobhan, G.R. Anderson, K.R. Singleton, A.E. Decker, P.S. Winter, J.W. Locasale, L. Crawford, A. Puissant#, and K.C. Wood# (2020). Using antagonistic pleiotropy to design a chemotherapy-induced evolutionary trap. Nature Genetics. 52: 408-417. [PDF] [Journal Link]
2019:
- T. Borgovan#, L. Crawford, C. Nwizu, and P. Quesenberry (2019). Stem cells and extracellular vesicles: biological regulators of physiology and disease. American Journal of Physiology-Cell Physiology. 317(2): C155-C166. [PDF] [Journal Link]
- L. Crawford#, S.R. Flaxman, D.E. Runcie, and M. West (2019). Variable prioritization in nonlinear black box methods: a genetic association case study. Annals of Applied Statistics. 13(2): 958-989. [PDF] [SI] [Software] [Journal Link]
- A. Monod#, S. Kališnik Verovšek, J.Á. Patiño-Galindo, and L. Crawford (2019). Tropical sufficient statistics for persistent homology. SIAM Journal on Applied Algebra and Geometry. 3(2): 337-371. [PDF] [Software] [Journal Link]
- D.E. Runcie# and L. Crawford (2019). Fast and general-purpose linear mixed models for genome-wide genetics. PLOS Genetics. 15(2): e1007978. [PDF] [SI] [Software] [Journal Link]
2018:
- L. Crawford#, K.C. Wood, X. Zhou#, and S. Mukherjee# (2018). Bayesian approximate kernel regression with variable selection. Journal of the American Statistical Association. 113(524): 1710-1721. [PDF] [SI] [Software] [Journal Link]
- R. Soderquist, L. Crawford, E. Liu, M. Lu, A. Agarwal, G.R. Anderson, K.H. Lin, P.S. Winter, M. Cakir, and K.C. Wood# (2018). Systematic mapping of BCL-2 gene dependencies in cancer reveals molecular determinants of BH3 mimetic sensitivity. Nature Communications. 9(1): 3513. [PDF] [Journal Link]
2017:
- K.R. Singleton*, L. Crawford*, E. Tsui, H.E. Manchester, O. Maertens, X. Liu, M.V. Liberti, A.N. Magpusao, E.M. Stein, J.P. Tingley, D.T. Frederick, G.M. Boland, K.T. Flaherty, S.J. McCall, C. Krepler, K. Sproesser, M. Herlyn, D.J. Adams, J.W. Locasale, K. Cichowski, S. Mukherjee, and K.C. Wood (2017). Melanoma therapeutic strategies that select against resistance by exploiting MYC-driven evolutionary convergence. Cell Reports. 21(10): 2796-2812. [PDF] [SI] [Software] [Journal Link]
- L. Crawford#, P. Zeng, S. Mukherjee, and X. Zhou# (2017). Detecting epistasis with the marginal epistasis test in genetic mapping studies of quantitative traits. PLOS Genetics. 13(7): e1006869. [PDF] [SI] [Software] [Journal Link]
- G.R. Anderson*, P.S. Winter*, K.H. Lin, D.P. Nussbaum, M. Cakir, E.M. Stein, R. Soderquist, L. Crawford, J.C. Leeds, R. Newcomb, P. Stepp, C. Yip, S.E. Wardell, J.P. Tingley, M. Ali, M. Xu, M. Ryan, S.J. McCall, A. McRee, C.M. Counter, C.J. Der, and K.C. Wood# (2017). A landscape of therapeutic cooperativity in KRAS mutant cancers reveals principles for controlling tumor evolution. Cell Reports. 20(4): 999-1015. [PDF] [Journal Link]
2016:
- G.R. Anderson, S.E. Wardell, M. Cakir, L. Crawford, J.C. Leeds, D.P. Nussbaum, P.S. Shankar, R.S. Soderquist, E.M. Stein, J.P. Tingley, P.S. Winter, E.K. Zeiser-Misenheimer, H.M. Alley, A. Yllanes, V. Haney, K.L. Blackwell, S.J. McCall, D.P. McDonnell, and K.C. Wood# (2016). PIK3CA mutations enable selective targeting of a breast tumor lineage survival dependency through MTOR-mediated control of MCL-1 translation. Science Translational Medicine. 8: 369ra175. [PDF] [Journal Link]
2014-2015:
- L. Crawford, V. Ponomarenko#, J. Steinberg, and M. Williams (2014). Accepted elasticity in local arithmetic congruence monoids. Results in Mathematics.66:227-245. [Journal Link]
Stay Connected
-
Address
1 Memorial Dr.
Cambridge, MA 02142
United States
-
Phone
857-453-6156
-
Email
lcrawford (at) microsoft (dot) com